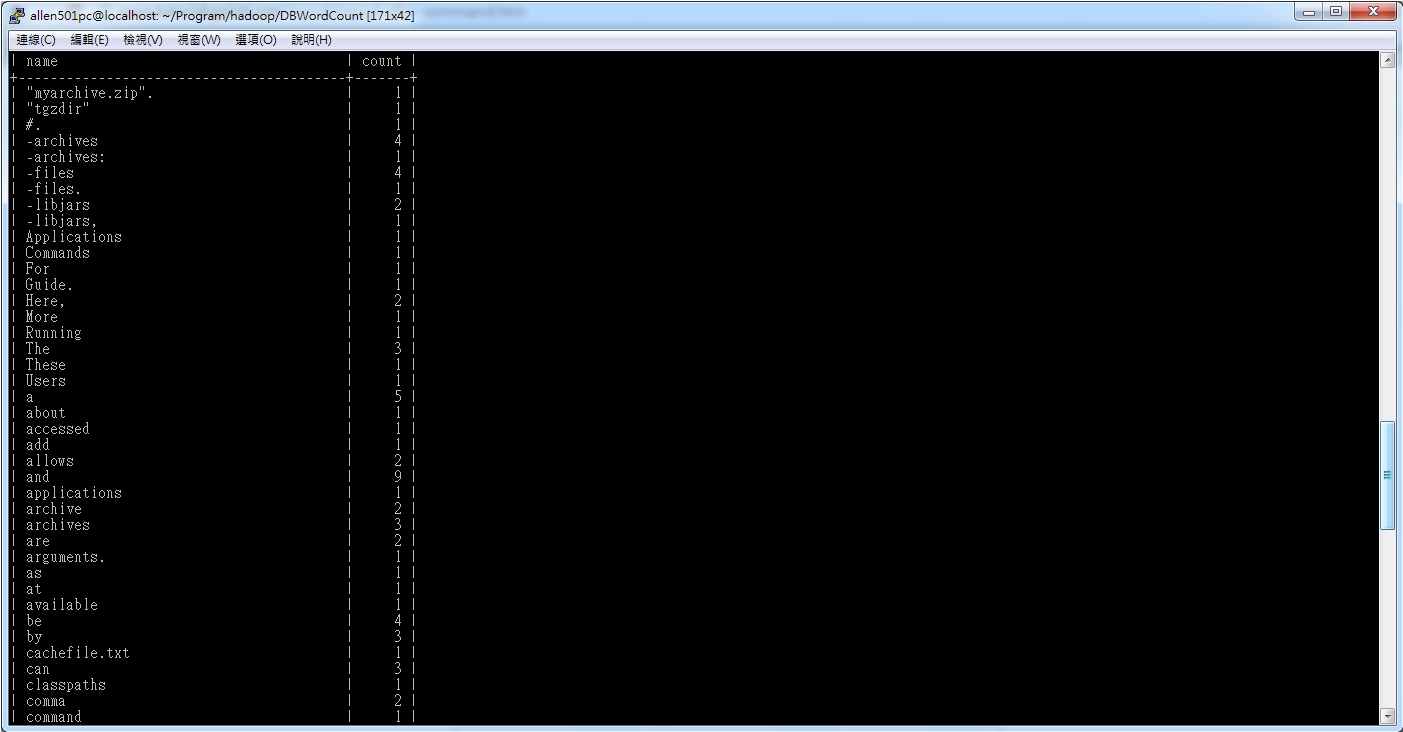
哈哈!終於搞定了!
卡了那麼久,竟然有一行根本不該加進去的。
話不多說,先說明接下來的Code該做什麼?
首先,我修改了Hadoop WordCount範例,主要是把HDFS中的input/input.txt,透過WordCount Map/Reduce後的資料,餵進MySQL資料庫。
依照以下步驟:
1. 建立資料庫:
DROP TABLE IF EXISTS `WordCount`.`Counting`;
CREATE TABLE `WordCount`.`Counting` (
`name` char(48) default NULL,
`count` int(11) default NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
import java.io.DataInput;
import java.io.DataOutput;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.mapred.lib.db.DBWritable;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
/*
MySQL DB Schema:
DROP TABLE IF EXISTS `WordCount`.`Counting`;
CREATE TABLE `WordCount`.`Counting` (
`name` char(48) default NULL,
`count` int(11) default NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
*/
public class DBWordCount {
// Output Record Object
static class WordCountInfoRecord implements Writable, DBWritable
{
public String name;
public int count;
public WordCountInfoRecord() {
}
public WordCountInfoRecord(String str, int c)
{
this.name = str;
this.count = c;
}
public void readFields(DataInput in) throws IOException {
this.name = Text.readString(in);
this.count = in.readInt();
}
public void write(DataOutput out) throws IOException {
Text.writeString(out, this.name);
out.writeInt(this.count);
}
public void readFields(ResultSet result) throws SQLException {
this.name = result.getString(1);
this.count = result.getInt(2);
}
public void write(PreparedStatement stmt) throws SQLException {
stmt.setString(1, this.name);
stmt.setInt(2, this.count);
}
public String toString() {
return new String(this.name + " " + this.count);
}
}
public static class Map extends MapReduceBase implements Mapper<LongWritable, IntWritable,Text,IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, WordCountInfoRecord, NullWritable>
{
public void reduce(Text key, Iterator<intwritable> values, OutputCollector<
WordCountInfoRecord, NullWritable=""> output, Reporter reporter) throws IOException
{ int sum = 0; while (values.hasNext()) { sum += values.next().get(); } // Output Data into MySQL output.collect(new WordCountInfoRecord(key.toString(),sum), NullWritable.get()); } } public static void main(String[] args) throws Exception { // The following is basic wordcount JobConf conf = new JobConf(DBWordCount.class); conf.setJobName("MySQL DB Wordcount"); Class.forName("com.mysql.jdbc.Driver"); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(DBOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); // Setup MySQL Connection , default account:root , no password String[] MyDBPath={"jdbc:mysql://localhost:3306/WordCount","你的帳號", "你的密碼"}; DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver",MyDBPath[0], MyDBPath[1], MyDBPath[2]); // Setup Output MySQL Format DBOutputFormat.setOutput(conf, "Counting","name", "count"); // Set Mapper and Reducer Class conf.setMapperClass(Map.class); //conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); // I've tried all combinations , but the bug still happen. conf.setMapOutputKeyClass(Text.class); conf.setMapOutputValueClass(IntWritable.class); conf.setOutputKeyClass(WordCountInfoRecord.class); conf.setOutputValueClass(NullWritable.class); JobClient.runJob(conf); } }
3. 撰寫以下Makefile:
# Author: Jyun-Yao Huang (allen501pc@gmail.com)
## Set up class path.
CLASSPATH=/opt/hadoop/hadoop-0.20.2-ant.jar:/opt/hadoop/hadoop-0.20.2-tools.jar:/opt/hadoop/hadoop-0.20.2-core.jar:/opt/hadoop/lib/mysql-connector-java-5.1.16-bin.jar:./
## Set up src files.
SRC = DBWordCount.java
## Set up class files.
OBJ = $(SRC:.java=.class)
## Set up jar file.
JAR_FILE = DBWordCount.jar
## Set up main function.
MAIN_FUNC = DBWordCount
all: $(OBJ)
jar -cvf $(JAR_FILE) DBWordCount*.class
make help
%.class: %.java
javac -classpath $(CLASSPATH) $<
clean:
hadoop fs -rmr output
cleanall:
rm *.class *.jar
hadoop fs -rmr output
run:
hadoop jar $(JAR_FILE) $(MAIN_FUNC) input/input.txt
help:
@echo “==============HELP=====================”
@echo “make run”
@echo “=====END================”
4. 輸入以下指令:
make , make run.
大功告成!
最後,附上一張MySQL DataBase結果輸出: